
Eigentlich einfach: Mit dem Canonical Attribut können wir im HTML <head> (oder, auch wenn es seltener vorkommt, im HTTP Response Header) angeben, ob es sich bei der URL um das Original oder eine Variante handelt. Varianten können aus verschiedenen Gründen entstehen, beispielsweise durch:
-
mobile URLs wie https://m.example.com/
-
Tracking-Parameter wie https://example.com/?utm_source=newsletter
-
AMP-Versionen wie https://example.com/amp/doc.html
-
Content-Übernahmen
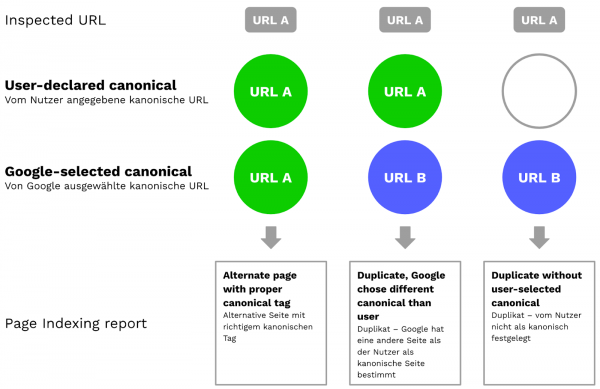
Mit dem URL Inspection Tool der GSC (oder im größeren Stil auch über die dazugehörige API, z. B. in Verbindung mit dem Screaming Frog) können wir im Abschnitt "Indexierung" sehen, welche URL wir im Canonical angegeben haben und für welche URL sich Google entschieden hat.
Im Fall unserer Startseite beispielsweise ist alles paletti: Wir haben im Canonical https://wngmn.de/ angegeben und Google hat diese URL ebenfalls als Canonical gewählt.

Vor allem, wenn das "User-declared canonical" – also die "Vom Nutzer angegebene kanonische URL" und das "Google-selected canonical" – also die "Von Google ausgewählte kanonische URL" voneinander abweichen, lohnt es sich auf jeden Fall zu prüfen, warum das so ist. Dabei hilft auch der Page Indexing Report weiter.
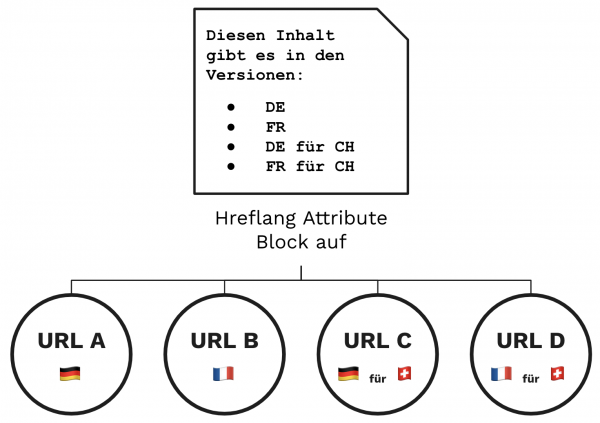
Soweit alles klar. Genauso wie beim Hreflang Attribut: Dieses kommt bei Websites zum Einsatz, die – entweder auf einer oder verteilt über mehrere Domains – Inhalte für verschiedene Länder und/oder in unterschiedlichen Sprachen bereitstellen. Mit Hreflang können wir angeben, in welcher Sprache und/oder für welches Land ein Inhalt gedacht ist. Außerdem lassen sich damit Beziehungen zu entsprechenden Inhalten in anderen Sprachen oder Ländern herstellen.
So weit, so gut. Beide Konzepte sind an sich gut nachvollziehbar. Allerdings kriegt man ein Problem, wenn man die beiden zusammen in einen Mixer wirft. Vanessa von SEOCATION hat die Thematik letzte Woche bei LinkedIn aufgegriffen. Denn in der Google Search Console werden dank der Canonical Consolidation seit April 2019 die Leistungsdaten von Duplikaten zusammengefasst und nicht mehr einzeln ausgewiesen.
Neben kanonikalisierten Dokumenten (z. B. mobile URLs, URLs mit Tracking-Parametern und AMP-URLs), sind auch gleichsprachige Dokumente betroffen, die mit Hreflang gekennzeichnet sind. Im Fall oben beispielsweise die beiden deutschsprachigen Versionen oder die beiden französischsprachigen Versionen. In Vanessas Beispiel auf LinkedIn geht es auch sehr klassisch um eine .de und eine .at Domain.
Zur Veranschaulichung der Canonical Consolidation eine kleine Visualisierung:
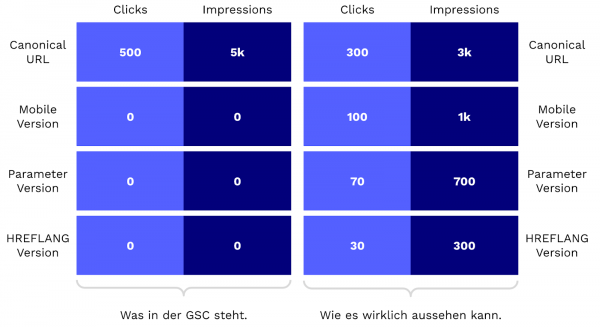
Wir nennen dieses Phänomen intern gerne auch "Canonical Hreflang Fuckup". Aber: Gibt es wirklich ein Problem und muss man etwas dagegen unternehmen? In den Kommentaren unter Vanessas Post wird beispielsweise der Ansatz der Lokalisierung diskutiert.
Die Idee hier: Die aktuell identischen Inhalte in einer Sprache für zwei Länder so anpassen, dass sie nicht mehr als Duplikate erfasst und zusammengelegt werden. Es gibt Fälle, in denen das sinnvoll und empfehlenswert ist. Angenommen, es geht um Fahrräder: Die heißen in der Schweiz gar nicht Fahrräder, sondern Velos.
Aber: Eigentlich ist alles okay. Also zumindest, wenn Du Deine Canonicals und Hreflangs alle ordentlich gesetzt hast und es kein Problem mit der Ausspielung der unterschiedlichen Versionen innerhalb der Google Suche gibt. Wenn Suchende in Deutschland die .de Domain angezeigt bekommen und die in Österreich die .at Domain, ist alles wunderbar. Wie Johan auch in einem der Kommentare schreibt – auch wenn in der Darstellung verschiedene URLs und ihre Leistungsdaten zusammengezogen werden:
"User bekommen in den Suchergebnissen aber die passende URL angezeigt, nicht immer das Canonical."
Ganz ehrlich, es ist nervig und nicht intuitiv, dass die Darstellung der Daten innerhalb der GSC nicht der eigentlichen Wahrheit entspricht. Wenn es darüber hinaus kein Problem gibt und eine angemessene Lokalisierung implementiert ist, musst Du hier keine zusätzlichen Ressourcen investieren. Wenn Dich das Canonical Hreflang Fuckup noch nicht genug frustriert hat, dann empfehle ich Dir die Lektüre von Behrends Wissensbeitrag: In "GSC: Zahlen, Daten, Fakten Fuckups Feedback" beschreibt er viele weitere Tücken, die einem beim Betrachten von GSC-Daten aufs Glatteis führen. Enjoy 😅