
Dass ich da noch nie selbst drauf gekommen bin! Manchmal ist man aber auch einfach in seinen Prozessen, Tools und Workflows sowas von eingefahren, dass man nicht mal mehr überlegt, ob es noch Alternativen zur Lösung gibt, die vielleicht noch den ein oder anderen Mehrwert mit sich bringen.
Gestolpert bin ich über diesen Artikel von Search Engine Land, in dem 5 Alternativen zur Wayback-Machine aufgezeigt werden. Zugegeben, spätestens seit die MS-DOS-Games hier verfügbar sind, fällt es auch ungemein schwer, sich mal die anderen Partys anzuschauen.
Memento
Der erste Tipp versprach mir viel und sollte eigentlich ein Aggregator sein, der u.a. auch die Ergebnisse der Wayback-Machine mit ausgibt, aber in meinem Test hat hier leider alles in einem 502-Bad-Gateway geendet.
Es hätte so schön werden können, denn versprochen wurde im Artikel:
- Auflistungen anderer Archive
- einem eigenen Chrome-Plugin mit Evergreen-Snapshot-Funktion
Gerade Letzteres ist sicher nicht nur für Marketer, sondern auch für (Abmahn-)Anwälte interessant. Der Plugin-Ansatz, direkt von der aktuellen Seite in ein Archiv zu springen ist in jedem Fall auch eine gute Idee. Ich hoffe, dass Bad Gateway wird schnell wieder gesund.
Archive.today
Die Funktion ist hier ziemlich ähnlich der Wayback-Machine und – trotz für mich schwieriger Bedienbarkeit – am Ende mit schnelleren Ergebnissen. In jedem Fall eine gute Ergänzung.
So sah beispielsweise die Startseite von Amazon am 19.10.2006 aus: https://archive.ph/Xt2T9
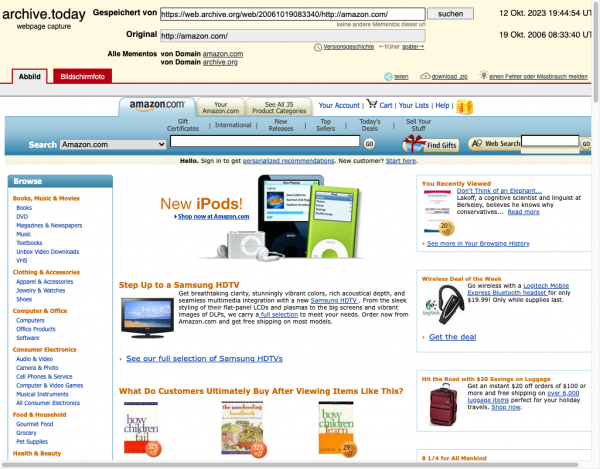
Nette Features sind die direkte Download-Möglichkeit als ZIP und ein separater Screenshot neben dem klickbaren Abbild der Seite.
Richtig gut ist die Suchfunktion, mit der sich die Archive mit modernen Mitteln durchstöbern lassen. Und YES... auch hier gibt es eine Chrome Extension und sogar eine Android App.
WebCite
DAS könnte mal wieder spannend werden und wandert bei mir in den Wiedervorlage-Topf. Aktuell scheint es keine neuen Anfragen zu verarbeiten, aber wenn es das tut, dann werden Dokumente und deren Links in Einzelbestandteile zerlegt und je Link einzeln abgelegt. Insbesondere wenn man gerne möchte, dass Menschen sich Abbilder einer Publikation anlegen können, ist man hier richtig.
Anwendungsfälle:
- Autoren und Verlage können Manuskripte direkt in WebCite hochladen, um sicherzustellen, dass Zitate gültig bleiben.
- Autoren, die Inhalte erstellen, können WebCite-Links zu ihren Seiten hinzufügen, so dass die Leser auf einfache Weise Schnappschüsse des Inhalts erstellen können, um später darauf Bezug zu nehmen oder zu zitieren.
- Medizinische Forscher können permanente Links zu Online-Zusatzmaterialien für ihre veröffentlichten Arbeiten erstellen und so sicherstellen, dass die Ressourcen für die Leser zugänglich und unverändert bleiben.
- Juristen können mit WebCite webbasierte Beweismittel archivieren und so sicherstellen, dass der Inhalt unverändert und vor Gericht zulässig bleibt.
GitHub
Wait... what? GitHub... hatte ich bisher "nur" für Coding-Versionierung und Code-Library abgespeichert. Ist es auch, aber DEVs diskutieren auch über Dinge, nutzen GitHub als Wiki UND man kann ein bisschen in die Entwicklung hineinspicken wie zum Beispiel hier bei Yoast.
Custom Archives
SEHR gute Idee... Archive-It (und bestimmt auch noch weitere Services) bietet die Möglichkeit, sich ein eigenes Archiv anzulegen. Viele Universitäten, Bibliotheken und Forschungseinrichtungen nutzen dies für sich.
Beispiele aus dem Artikel sind:
- The UK Web Archive (Achtung, langsam)
- The Library of Congress Web Archive
- Web Archive Singapore (Achtung, langsam)
- The Croatian Web Archive
Welches ist Dein Lieblingsarchiv?
Generell eignen sich Archive in der täglichen SEO-Arbeit für:
- Die Suche nach Lost oder Broken Links
- Für Wettbewerbsanalysen
- Zur Identifikation von Verlinkungsmöglichkeiten
- Zum Monitoring von SERP Changes
- Zur Plagiatskontrolle
- Für Content Gap Analysen
- Um Algo Update zu tracken
- Um gelöschten Inhalt wieder zu reaktivieren
- Zur Suche nach historischen Trends
- Zum Aufdecken von SEO-Unfug von Damals™️