Die letzten Jahre habe ich mich intensiv mit Indexierung auseinandergesetzt. Ich finde das faszinierend: Wie speichere ich einmal Internet so, dass es in Bruchteilen von Sekunden durchsuchbar ist.
Die Mengen und Dimensionen, in denen hier gearbeitet werden muss, sind einfach Mindblowing. Kein Wunder, dass das Indexing-System bei Google nach der Bibliothek von Alexandria benannt wurde.
Aber darum soll es gar nicht gehen.
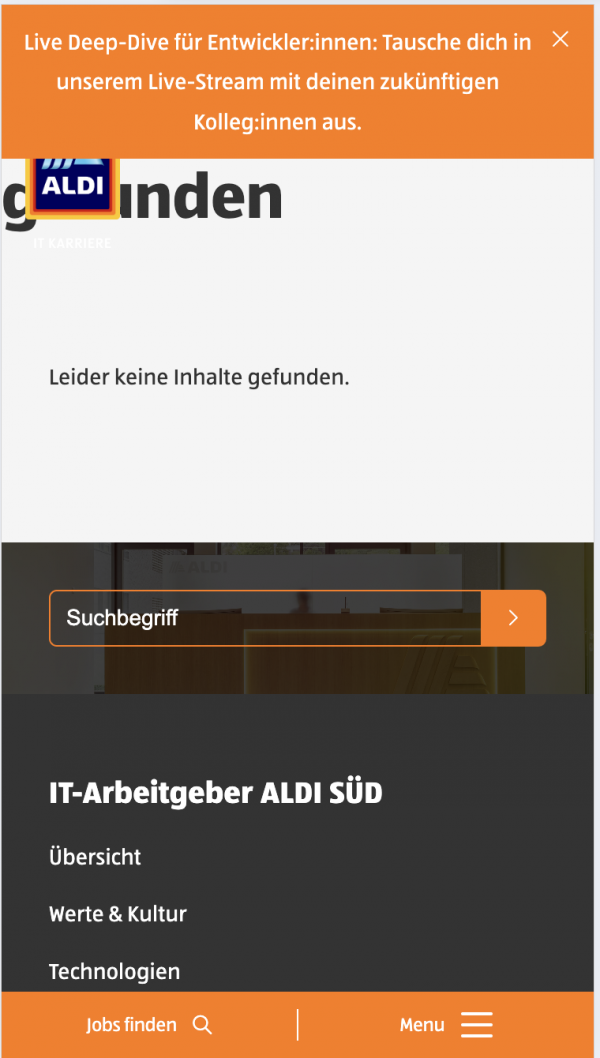
Im Indexierungsprozess werden Dokumente nicht berücksichtigt, die nicht indexierungswürdig sind. 404-Seiten oder Dokumente, die als Noindex gekennzeichnet sind beispielsweise. Es gibt aber viele Seiten, die liefern ein sinnloses Ergebnis, das eigentlich nicht verfügbar sein sollte, als indexierbare Seite mit dem Status Code 200 aus. Ein Beispiel wären leere Suchergebnisseiten.
Das sieht dann etwa so aus:

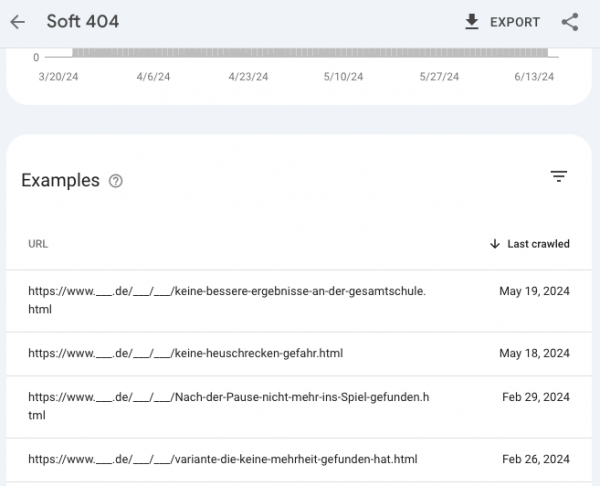
Während eines Routine-Rundgangs durch die Search Console kann man jetzt gut sehen, wie ein Teil der Heuristik zur Erkennung und Aussortierung solcher Seiten aussieht. Denn logischerweise möchte Google solche Seiten eigentlich nicht indexieren. Sie lassen Google schlecht dastehen, denn ein Klick aus den Google-Suchergebnissen auf ein Ergebnis sollte mich immer näher an das Ziel führen.
Im Screenshot aus der GSC ist gut zu erkennen, dass Google die Fehler vor allem auch an URL und Überschrift fest macht. Bei den Seiten handelt es sich um Nachrichten-Artikel:
-
Keine bessere[sic!] Ergebnisse an der Gesamtschule
-
Keine Heuschrecken-Gefahr
-
Nach der Pause nicht mehr ins Spiel gefunden
-
Variante die keine Mehrheit gefunden hat
Gut zu sehen, wie der Collapsor (so heißt der Prozess / das System bei Google, das die Analyse auf Soft-404 vornimmt) arbeitet. Gary hat das System vor ein paar Jahren im Search Off the Record-Podcast vorgestellt.
Vor allem auf die Worte „Keine" und „Nicht" reagiert das System sehr deutlich. Wenn Du also sichergehen willst, dass Google Deine Inhalte indexiert und nicht als Soft-404 behandelt. Dann solltest Du gelegentlich schauen, dass Du Verneinungen in den Headlines vermeidest. Meistens funktioniert die Indexierung trotzdem. Aber hier ist Machine Learning am Werk und das kann dann auch mal schief gehen.