
Die Frage, wie Inhalte von Webseiten für KI-Modelle wie ChatGPT oder Gemini zugänglich sind, entwickelt sich derzeit zu einem Prüfpunkt für technische Auslesbarkeit. Denn während Nutzer und Nutzerinnen längst an nahtlose, interaktive Oberflächen gewöhnt sind, wie schnelle Filter, dynamische Nachlade-Prozesse oder personalisierte Inhalte, basiert vieles davon auf JavaScript. Für Nutzer ist das selbstverständlich und kaum wahrnehmbar. Für Large Language Models hingegen entsteht damit eine unsichtbare Wand: Was im Browser flüssig funktioniert, bleibt für KI-Systeme oft unlesbar.
Damit prallen zwei Welten aufeinander: Auf der einen Seite moderne Frontend-Technologien, die das Nutzererlebnis perfektionieren sollen, auf der anderen Seite Sprachmodelle, die Inhalte nur so gut interpretieren können, wie sie technisch zugänglich gemacht werden. Das Resultat: Viele Produktinformationen, Preise oder Beschreibungen, die für User elementar sind, verschwinden für KI-Modelle in einer Blackbox. Wenn ich also ChatGPT frage, welche Produkte Firma XY anbietet, kann es mir keine Aussagen darüber machen.
Was ist das Problem?
ChatGPT und Gemini erkennen zwar, dass es sich bei Kategorieseiten um solche handelt, können die Inhalte jedoch nicht lesen, wenn diese aus clientseitig gerendertem JavaScript bestehen. Auch Produktdetailseiten verlieren ihren Informationswert für LLMs, wenn Inhalte ausschließlich clientseitig nachgeladen werden.
Selbst korrekt eingebundenes JSON-LD im Quelltext wird von LLMs nicht zuverlässig verarbeitet, um Aussagen über Seiteninhalte zu generieren. Innerhalb eines <script>-Tags bleiben Daten für diese Modelle praktisch unsichtbar.
Gerade bei Gemini, dessen Nähe zu Google eigentlich vermuten ließe, dass es Scripts problemlos ausliest, fällt die eigene Erklärung des Modells überraschend nüchtern aus: Das Problem ist nicht das Vorhandensein von Markup, sondern dass seine Werkzeuge nicht darauf ausgelegt sind, strukturierte Daten in Skripten zu parsen.
Schema bleibt trotzdem wichtig. Wer es konsequent pflegt, gewinnt Relevanz im etablierten Such-Ökosystem und positioniert sich auch für AI, nur im direkten Grounding-Prozess aktueller Sprachmodelle liefern strukturierte Daten bislang keinen messbaren Vorteil.
Wer sich zukunftssicher aufstellen will, sollte auf technische Auslesbarkeit setzen:
Server-Side Rendering einsetzen, um Inhalte nicht ausschließlich clientseitig nachzuladen und regelmäßig prüfen, wie Bots und LLMs Inhalte tatsächlich sehen. Tools, die eine nicht gerenderte Ansicht zeigen, offenbaren oft erschreckend leere Ergebnisse.
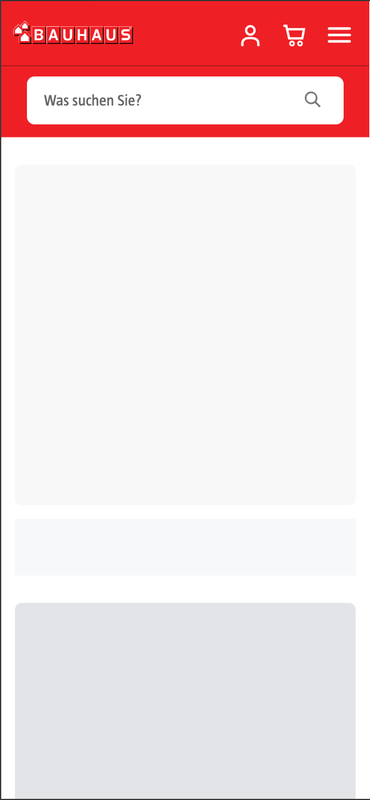
Am Beispiel von Bauhaus wird deutlich, was der Nutzer sehen kann

und was das LLM sieht, nämlich nichts.
Agentenmodus vs. Standardmodus
Ein Sonderfall ist der so genannte Agentenmodus von ChatGPT. Hier wird von dem LLM ein echter Browser genutzt, der JavaScript rendert. Doch der Agentenmodus ist kein Standard und für die meisten Anwendungen von AI in Such- und Assistenzfunktionen bleibt die Limitierung bestehen.
Fazit
AI-Readiness ist weniger eine Frage von Markup als von technischer Transparenz. Inhalte, die nur über JavaScript ausgeliefert werden, bleiben für aktuelle Inferences, die mit dem Server zugreifen, unsichtbar.
Und klar ist auch: Die Entwicklung schreitet rasant voran. In den kommenden Monaten wird sich zeigen, ob und wie schnell sich die Fähigkeiten von LLMs beim Auslesen von Strukturierten Daten und JavaScript weiterentwickeln und welche neuen Chancen oder Hürden dadurch entstehen. Deine rasenden Reporter bleiben an der Sache dran.