
Letzte Woche habe ich Dir den Google Leak vorgestellt und Dir versprochen, Dich ein wenig auf meine Erkundungsreise mitzunehmen. Einen guten ersten Eindruck bekommst Du vom Leak, wenn Du Dir mein Gespräch mit Alex und Marcus in der täglichen Dosis SEO dazu anschaust. In der Show habe ich unter anderem eine Visualisierung von Natzir gezeigt.
Die Streamlit-App stellt den Leak (die Module) als Graph dar. Das habe ich in der Show kritisiert, weil zum einen nicht transparent ist, wie die Visualisierung zustande kommt, und zum anderen man nicht weiß, welche der Module denn jetzt gezeigt werden und welche nicht.
Dennoch ist die Idee, sich das einmal als Netzwerk zu visualisieren, extrem hilfreich. Und als alter SEO-Hase ist das eine tolle Möglichkeit, Gephi mal wieder zu entstauben. Ich habe also fix mit dem ScreamingFrog einen Crawl des Leaks angeworfen und die Links exportiert. Die Links noch fix bereinigt (so dass die Template-Links rausfliegen) und dann in Gephi importiert.
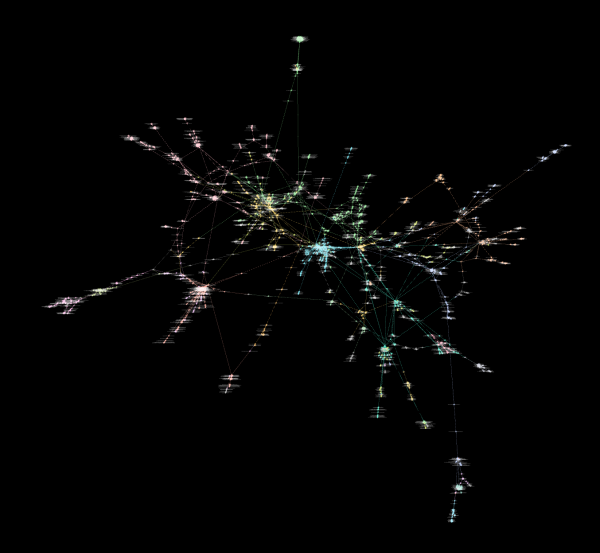
Netzwerk-Visualisierung in Gephi. Man erkennt mehrere Hubs/Ballundsräume, die klar voneinander getrennt sind.
Damit ein wenig Farbe ins Spiel kommt, habe ich die 3000 Module in einzelne Gruppen zerlegt. Alles was mit Crawler zu tun hat, oder mit Snippet hat eine entsprechende Gruppe bekommen und diese Gruppe eine Farbe.
Um Dir einen Überblick zu geben, habe ich die einzelnen Cluster einmal beschriftet:
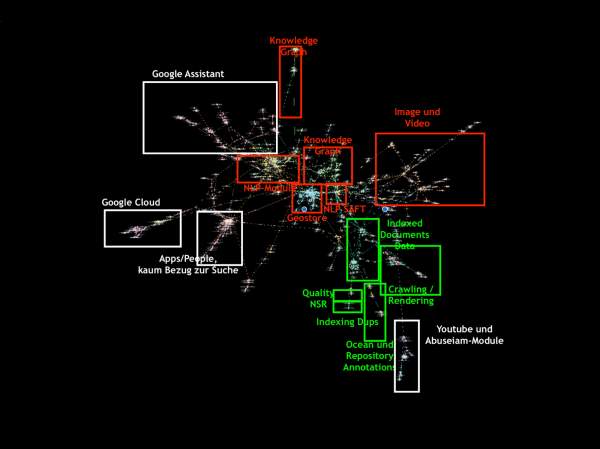
Auf der linken Seite sehen wir 3 (weiße) Gruppen:
-
Google Assistant
-
Google Cloud
-
und Apps/People
Diese Module sind recht klar vom Rest separiert und hängen nur an wenigen Kanten mit den anderen Modulen zusammen. Eine interessante Verbindung des People-Netzwerkes besteht über eine Node aus dem Authorship-Module des Science-Netzwerks.
Einen weiteren Hub habe ich weiß markiert. Der befindet sich rechts unten und enthält eine Menge Module zu Youtube. Hinter Youtube hängen dann viele der Abuseiam-Module (Diese Module habe ich auch im Video angedeutet, dass die zwar spannend klingen, aber nicht so spannend zu sein scheinen auf den ersten Blick.).
In Rot habe ich dann Module markiert, die mit der Suche zu tun haben, aber etwas separierter von den Kernmodulen sind:
-
Es gibt zwei voneinander klar abtrennbare Knowledge-Graph- / Entity-Module.
-
Ein sehr großes Cluster setzt sich mit NLP-Funktionen auseinander
-
Ebenfalls recht groß ist das Geostore-Modul, das Geo-Informationen und Maps-Infos bereit hält. Hier gibt es nicht nur Informationen über local Businesses, sondern auch über PriceRanges, Speedlimits oder NutritionFacts. Nicht überraschend, dass hier im Cluster auch einige Webref- und Freebase-Module (die eigentlich weiter oben in Knowledge Graph einen Schwerpunkt haben) auftauchen
-
Neben dem Geostore finden wir ein weiteres NLP-Modul: NLP-Saft. Mit diesen Modulen scheint Google strukturierte Daten aus Text-Informationen abzuleiten.
-
Und rechts oben finden wir dann Images und Videos (die mich (noch) nicht so interessieren)
Als drittes habe ich dann in grün die Kernfunktionen markiert:
-
Es gibt ein großes Cluster mit mindestens 2 klaren Subclustern zu indexierten Dokumenten.
-
Daneben befinden sich Crawling und Rendering.
Und 3 weitere Gruppen, die extrem spannend aussehen:
-
Quality NSR: Hier sammelt Google Informationen über die Qualität von Seitenbereichen.
-
Indexing Dups: Hier werden Duplikatsinformationen (Canonical, etc.) gesammelt. (Es ist Zufall, dass es so aussieht, als würde dieses Modul hinter der NSR-Gruppe hängen. Tatsächlich hängen beide am PerDocData-Modul.)
-
Ocean-Repository und Annotations. Hierüber weiß ich noch nicht viel, aber ich bin seeeehr neugierig, was es hier zu finden geben wird.
Natürlich kann man in Gephi noch weitere Spielereien vornehmen. Ich habe beispielsweise einen PageRank aller Module berechnet:
- Den höchsten PageRank hat AppsPeopleOzExternalMergedpeopleapiPersonFieldMetadata: "Metadata for a single Person field. See go/understanding-merged-person"
Danach kommen:
-
Proto2BridgeMessageSet: "This is proto2's version of MessageSet." Hierbei handelt es sich anscheinend um einen sehr flexibel einsetzbaren Protocol-Buffer. Da es hier keine Outlinks gibt, aber das Modul häufig eingesetzt wird, ist es kein Wunder, dass es einen hohen PageRank hat
-
GeostoreFeatureIdProto: "A globally unique identifier associated with each feature."
-
NlpSemanticParsingAnnotationEvalData: "Annotators whose semantics are represented via a protocol message should add to that message a field or extension of this type and set it using Annotator::PopulateAnnotationEvalData to enable span-based evaluation metrics in training. Evaluation is done based on token spans. "
-
GeostoreFieldMetadataProto: "Internal field metadata."
-
NlpMeaningMeaningRemodelings: "This proto will be added as a field to part of a schema to indicate it is being remodeled."
Nicht besonders viel Gold auf diesem Weg zu finden. Aber: Das ist auch logisch: Alle diese Module verweisen nicht auf andere Module. Der PageRank fließt also nicht hindurch, sondern wird hier gesammelt.
Also habe ich ebenfalls eine Hubs and Authorities-Kalkulation angeworfen. Die wirft als Top5 andere Hubs aus:
-
GeostoreFeatureProto: Ein zentraler Protocol Buffer der Geostore-Module
-
NlpSemanticParsingQRefAnnotation: "The QRefAnnotator annotates spans of input with freebase-ids and collection-information." 🧐
-
GeostoreRelationProto: " represents a geographic or logical relationship of that feature to some other feature"
-
PerDocData: Das scheint das zentrale Modul zu sein, in dem alle Informationen über ein Dokument gesammelt werden.
Da Du nur Visualisierungen trauen solltest, die Du selbst gefälscht hast, habe ich Dir mein Gephi-File als Ausgangspunkt einmal hochgeladen.
Einige Dinge, die Du bei den Graphen beachten solltest:
-
Die Anzahl der Module zu einem Thema gibt nicht zwangsläufig die Wichtigkeit dieser Module wieder.
-
Die Anzahl der Verknüpfungen zu anderen Modulen kann viele Ursachen haben
-
Eine starke Zentralität im Graphen oder starke Konnektivität bedeutet daher nicht, dass dieses Modul besonders großen Impact auf Deine Suchmaschinenperformance hat.
Dennoch können wir einige interessante Schlussfolgerungen aus der Visualisierung ziehen:
-
Viele Module haben keinen direkten Impact auf unsere Tätigkeit
-
Es gibt wesentlich mehr NLP-Module, als ich erwartet hätte. Das spricht dafür, dass diese Themen sehr modular und nicht monolithisch aufgebaut sind (und das ergibt auch Sinn, wenn man darüber nachdenkt).
-
Die Geostore-Module sind recht prominent (und zahlreich)
-
Die Visualisierung hilft uns, Zusammenhänge für einzelne Module besser zu verstehen.
Diese Woche werde ich mit Florian zusammen ein wenig über Theorie und Praxis der Funktionsweise einer Suchmaschine auf der Campixx sprechen) (Freitag, 12.30 Uhr Raum Wingmen).
Und nächste Woche werden wir in eines der zentralen Module tiefer eintauchen (vermutlich beginnen wir mit den Crawling-Modulen).