
Bei der täglichen Arbeit mit dem Screaming Frog und den Auswertungen der Daten hat mich immer der Umweg über die CSV-Exportdateien gestört. Gerade mit KNIME gehören fixe Prozesse und Daten-Sheets doch der Vergangenheit an. Im letzten Newsletter hatte ich angekündigt, dass ich Dir zeige, wie Du auf Screaming Frog Exporte direkt zugreifen kannst. Jedoch fand ich diesen (Um)Weg immer noch zu kompliziert. Aus diesem Grund habe ich mir die Frage gestellt, ob ein direkter Datenbankzugriff auf die Daten im Screaming Frog möglich ist.
Und die Antwort lautet „ja", solange Du in den Einstellungen den „Storage Mode" auf „Database Storage" gestellt hast, kannst Du direkt auf Deine Crawls mit SQL und etwas Magie zugreifen!

(Bild erstellt mit Bing Image Creator)
Wie das genau funktioniert und welche Schritte Du durchführen musst, um ebenfalls in den Genuss diesen genialen Features zu kommen, zeige ich Dir in diesem Step by Step Guide:
1. Derby-Treiber installieren
Als Erstes benötigen wir einen aktuellen Derby-Datenbank-Treiber, den wir hier herunterladen können. Der Treiber ist ein JDBC-Treiber und wird benötigt, damit KNIME (und andere Programme) auf die Screaming Frog-Daten zugreifen können. JDBC steht für „Java Database Connectivity" und ist eine universelle Datenbankschnittstelle für Java und in Java entwickelte Programme.
2. Wo findest Du nun Deine Crawl-Daten?
Dazu habe ich Dir ein kleines Tool in PHP gebastelt. Mit diesem kannst Du Dir den jeweils benötigten „Verbindungs-String" eines bestimmten Crawls anzeigen lassen. Danach musst Du diese Zeichenkette nur noch via Copy&Paste in Deine Programme übernehmen, um Dich mit dem jeweiligen Crawl zu „verbinden".
-
Öffne ein Terminal auf Deinem Rechner
-
Lade das Script an die Stelle, an der Du mit dem Script arbeiten möchtest.
-
Starte das Script mit dem Kommando "php sfadmin.php". Danach wirst Du dieses Menü sehen.
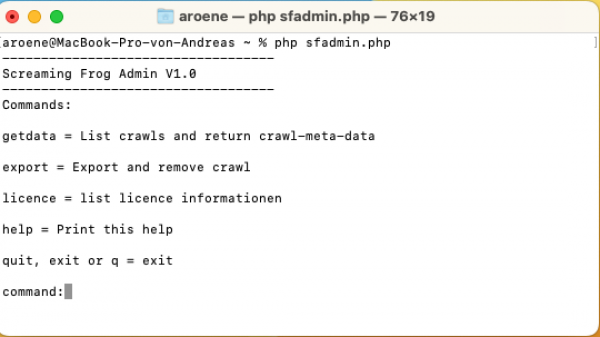
(Das Script wartet auf die Eingabe eines Kommandos)
- Gib das Kommando "getdata" ein. Das Script listet alle im Frog gespeicherten Crawls auf.
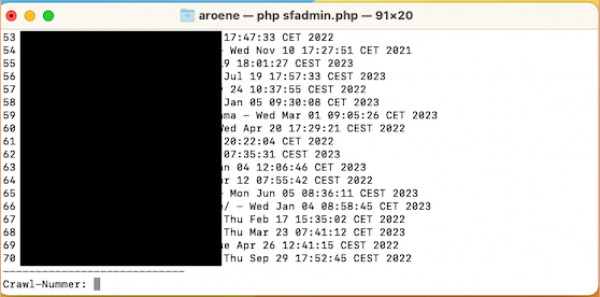
(Nach dem Kommando "getdata" listet Dir das Script alle verfügbaren Crawls auf.)
- Wähle jetzt Deinen gewünschten Crawl aus, indem Du die Zahl vor dem Crawl eingibst und dies mit Enter bestätigst. (0 bringt Dich zurück ins Hauptmenü)
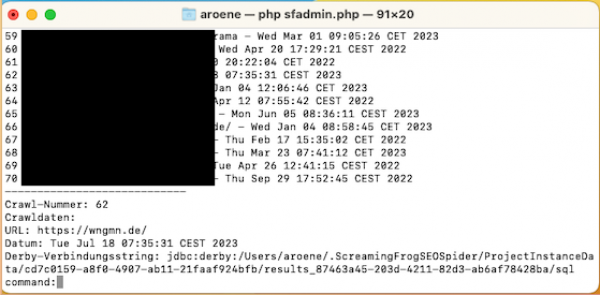
(Das Script gibt nun die wichtigsten Daten des Crawls aus. Unter anderem den Derby-Verbindungsstring)
-
Diesen String benötigen wir für die nächsten Verbindungen. Kopiere diesen bitte in die Zwischenablage.
-
Das Programm kannst Du mit dem Kommando "q" + Enter beenden
3. Erster Blick in die Datenbank mit DBeaver
Aber wozu benötigen wir jetzt den DBeaver? Ganz einfach: Derby unterstützt „nur" die Datenbanksprache SQL-92. Diese schränkt KNIME in der aktuellen Version noch sehr stark in der Zusammenarbeit mit Derby ein. Um Dir die Struktur der Datenbank besser zu verdeutlichen, nutzen wir ein freies Datenbank-Tool, das hier eine bessere Unterstützung bietet.
-
Daher laden wir DBeaver einmal herunter und installieren es.
-
Im nächsten Schritt legen wir im DBeaver eine neue Datenbankverbindung an. Dazu klicken wir auf das Icon oben links.
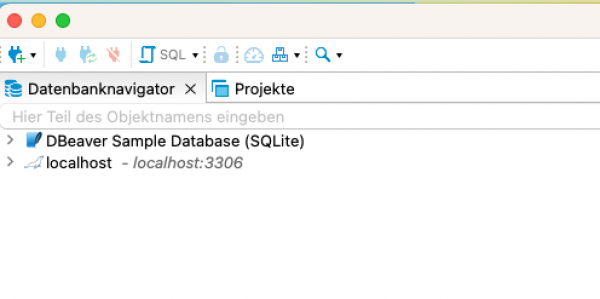
Datenbankverbindung anlegen:
Suche in den Verbindungen nach "Derby". Die Verbindungsart "Derby Embedded"ist die Version, die wir für den Frog verwenden müssen.
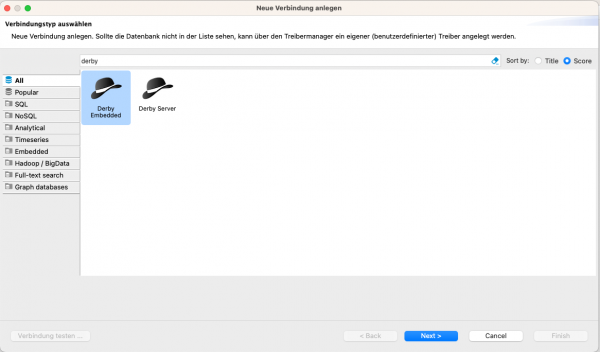
(Wähle in diesem Dialog "Derby Embedded" aus)
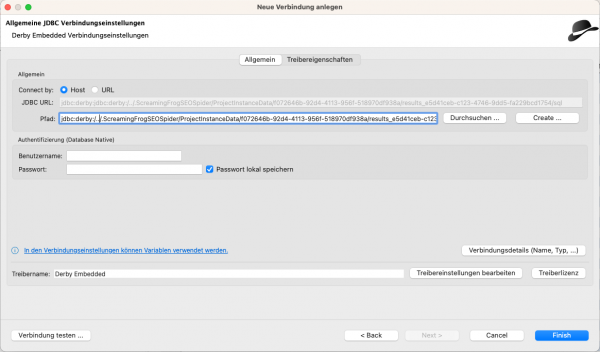
(Füge den Verbindungs-String aus der Zwischenablage in dem Feld "Pfad" ein.)
Prüfen, ob der Datenbanktreiber in der aktuellen Version 10.16.X genutzt wird:
Klicke dazu auf den Button "Treibereinstellungen bearbeiten"
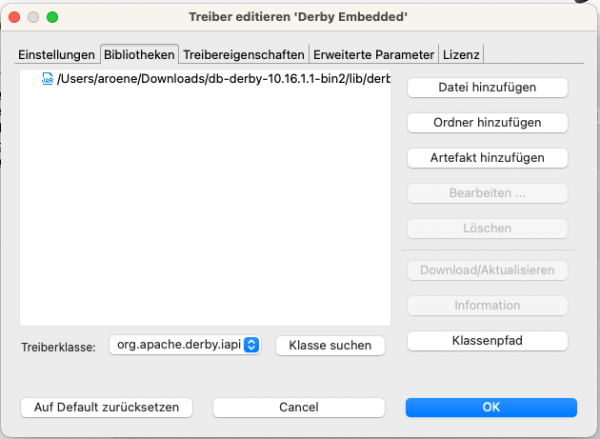
Sollte hier noch eine andere (ältere) Version installiert sein, so müssen wir diese entfernen und unsere als erstes heruntergeladenen Treiber über "Datei hinzufügen" einbinden. Suche in Deinem Download nach dem Verzeichnis "db-derby-10.16.x.x-bin", dort ist das Verzeichnis "lib" enthalten und darin die Datei "derby.jar". Diese musst Du in dem Dialog auswählen.
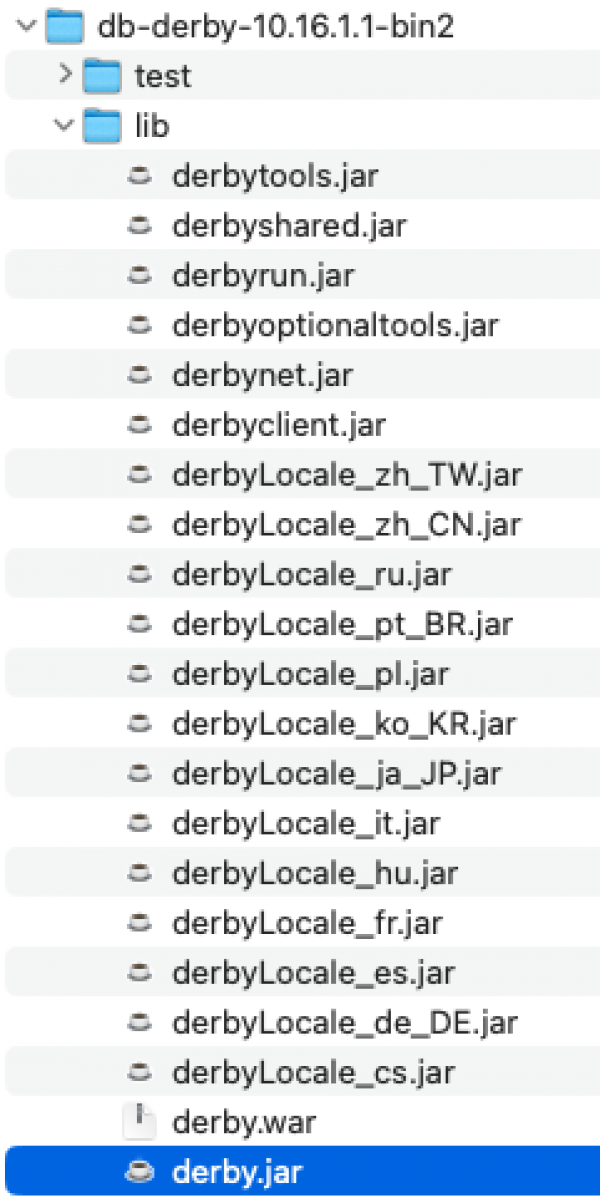
Danach kannst Du mit einem Klick auf "Klasse suchen" checken, ob der richtige Treiber gefunden und genutzt wird: Die Pull-down-Liste links neben dem Button sollte sich nun mit Klassennamen gefüllt haben. Ausgewählt ist hier "org.apache.derby.iapi.jdbc.AutoLoadedDriver".
Danach können wir den Dialog mit einem Klick auf "OK" schließen.
Das Verzeichnis zur eigentlichen Datenbank haben wir ja schon ausgewählt und so können wir den Dialog "Verbindungseinstellungen" ebenfalls mit einem Klick auf "OK" schließen.
Herzlichen Glückwunsch! Du hast Deine erste Datenbankverbindung eingerichtet. Du solltest nun in der Baumstruktur einen neuen Knoten mit Deiner Verbindung sehen. Wenn Du diesen nun mit einem Klick öffnest, erscheint die Datenbankstruktur Deines Crawls.
Was Du bei Deiner Arbeit mit Derby-Datenbanken beachten solltest:
-
Auf Derby-Datenbanken kannst Du nur mit Programmen zugreifen, die JDBC als Datenbankschnittstelle unterstützen. Dies sind in der Regel daher „nur" JAVA-Anwendungen
-
Programme haben auf Derby-Datenbanken im "Embedded" Modus einen exklusiven Zugriff. Das bedeutet, es kann immer nur ein Programm aktiv auf eine Datenbank zugreifen. Dies kann bei beim Wechsel zwischen DBeaver und KNIME häufiger mit einer Fehlermeldung enden. Du musst hier leider immer zwischen den Programmen sauber beenden bzw. die Datenbankverbindung schließen und nach kurzer Zeit benötigst Du DBever auch kaum noch, da Du die Struktur der Datenbank verinnerlicht hast.
Im nächsten Newsletter stellen wir dann die Verbindung direkt in KNIME her und erstellen die ersten Nodes.